Airbyte : l'outil open source d'intégration de données pour l'IA
Vos pipelines de données actuels sont-ils devenus le goulot d’étranglement silencieux de vos ambitions en intelligence artificielle ?
Alors que la grande majorité du temps des projets data est encore englouti par la préparation des données selon les standards du marché, l’incapacité à connecter rapidement des sources non structurées aux nouveaux modèles LLM paralyse l’innovation. Airbyte s’impose aujourd’hui comme la réponse technique pragmatique à ce défi d’infrastructure critique, redéfinissant les standards de l’intégration pour l’ère de l’IA générative.
I. L’architecture moderne d’intégration : pourquoi l’ELT open source change la donne pour l’IA
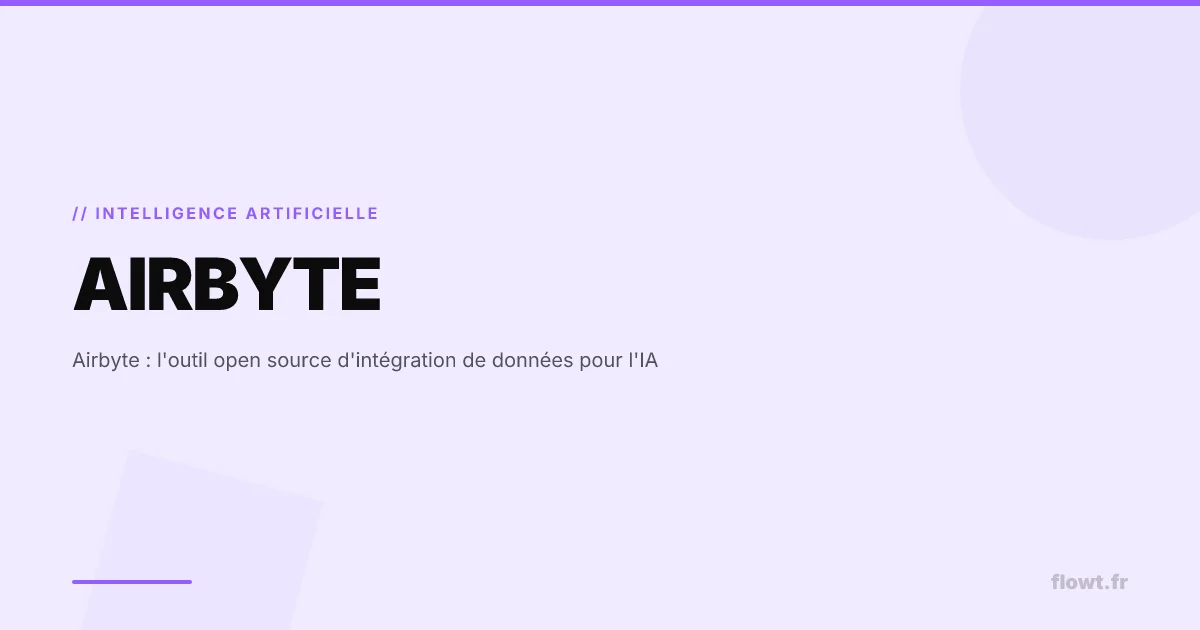
Comment fonctionne la standardisation ELT ?
a. La fin de l’ETL traditionnel face aux volumes non structurés
Les modèles d’IA modernes exigent une vélocité et une variété de données que les architectures ETL historiques peinent à supporter.
Le modèle ELT (Extract, Load, Transform) porté par Airbyte inverse la logique de traitement pour préserver la donnée brute, essentielle aux réentraînements futurs des modèles. Contrairement aux pipelines rigides qui imposent des schémas stricts dès l’extraction, cette approche permet de déverser l’intégralité des données brutes dans le data warehouse ou le data lake avant transformation.
Les avantages structurels de cette approche pour les environnements IA incluent :
- Découplage critique : L’extraction est séparée de la transformation, permettant aux Data Engineers de ne jamais casser le pipeline en cas de changement de schéma source.
- Support natif des formats IA : La capacité à ingérer des données non structurées (textes, logs, JSON complexes) sans pré-traitement lourd est native.
- Scalabilité horizontale : L’architecture basée sur des conteneurs Docker permet de paralléliser les syncs massifs nécessaires aux initialisations de modèles.
Cette flexibilité structurelle réduit de manière considérable la dette technique des équipes data, qui n’ont plus à maintenir des scripts d’extraction personnalisés fragiles. C’est un pilier essentiel d’une stratégie de Data Engineering moderne.
b. Le catalogue de connecteurs open source : un avantage stratégique
La force de frappe d’Airbyte réside dans sa communauté open source qui produit et maintient des connecteurs à une vitesse inégalable par un éditeur propriétaire.
Avec plus de 600 connecteurs référencés dans son catalogue officiel, la plateforme couvre non seulement les grands standards (Salesforce, HubSpot, PostgreSQL) mais surtout la “longue traîne” des API de niche cruciales pour des contextes métiers spécifiques. Le “Connector Builder” no-code permet désormais de générer un connecteur personnalisé très rapidement, là où cela demandait auparavant des jours de développement.
La réactivité de cet écosystème communautaire se traduit par plusieurs bénéfices opérationnels :
- Réactivité communautaire : Les mises à jour d’API (comme celles fréquentes de Facebook ou Google Ads) sont souvent patchées par la communauté en un temps record.
- Standardisation du protocole : Tous les connecteurs fonctionnent comme des images Docker indépendantes, garantissant qu’un bug sur une source n’impacte jamais le reste de l’infrastructure.
- Transparence du code : En cas de blocage, les équipes techniques peuvent auditer et modifier directement le code du connecteur, impossible avec une solution “boîte noire”.
Cette extensibilité illimitée assure aux entreprises qu’aucune donnée ne restera silotée faute de connecteur disponible.
c. PyAirbyte : le pont manquant entre Data Engineering et Data Science
L’introduction de la librairie PyAirbyte permet d’embarquer la puissance de l’outil directement dans les notebooks Python des Data Scientists.
Cette innovation technique supprime la friction historique entre les équipes d’ingénierie et les équipes de science des données. Un Data Scientist peut désormais instancier un pipeline d’extraction complet directement dans son environnement de travail (Jupyter, Databricks), sans attendre une mise en production complexe par l’équipe IT.
L’intégration de cet outil dans le workflow data science offre des capacités d’accélération majeures :
- Intégration LangChain : Les données extraites sont directement compatibles avec les frameworks d’orchestration LLM, facilitant les projets RAG (Retrieval-Augmented Generation).
- Cache local intelligent : PyAirbyte gère intelligemment la mise en cache locale, évitant de re-télécharger des volumes massifs de données à chaque itération du modèle.
- Compatibilité vectorielle : Le flux de données peut être dirigé nativement vers des bases de données vectorielles comme Pinecone ou Weaviate.
Cette capacité d’itération rapide accélère notablement le “Time-to-Model”, permettant de tester des hypothèses sur des données réelles sans délai.
Pour approfondir la structuration de vos équipes techniques, consultez notre article sur Monter un Data Lab : méthodologie, équipe et cas d’usage.
Cette convergence technique entre ingénierie et science des données soulève désormais la question de l’infrastructure spécifique requise pour les applications d’IA générative.
II. Airbyte comme moteur d’ingestion pour les pipelines RAG et GenAI
N’oubliez pas
a. L’alimentation automatisée des bases vectorielles
L’un des défis majeurs du RAG est de maintenir la base de connaissances de l’IA synchronisée avec les données de l’entreprise en temps quasi-réel.
Airbyte a développé des destinations spécialisées pour les bases de données vectorielles (Vector Databases), automatisant le processus complexe de “chunking” et d’embedding. Au lieu de construire des scripts Python ad-hoc pour découper les documents et appeler les API d’OpenAI, le pipeline gère ces étapes de manière transparente et industrielle.
Les fonctionnalités clés pour automatiser ces flux complexes comprennent :
- Synchronisation incrémentale : Seuls les nouveaux documents ou les documents modifiés sont traités et vectorisés, réduisant drastiquement les coûts d’API d’embedding.
- Gestion des métadonnées : Les connecteurs préservent les métadonnées sources (auteur, date, lien), cruciales pour le filtrage et la citation des sources dans les réponses du LLM.
- Choix du modèle d’embedding : La configuration permet de choisir flexibilité le modèle d’embedding (OpenAI, Cohere, ou local) directement dans l’interface.
Cette automatisation transforme la base vectorielle en un miroir fidèle et à jour de la connaissance d’entreprise, sans intervention manuelle.
b. Gestion des données non structurées à grande échelle
Les pipelines traditionnels sont conçus pour des lignes et des colonnes, alors que l’IA se nourrit principalement de textes, PDF, images et conversations.
La plateforme intègre désormais le traitement de ces données non structurées comme des citoyens de première classe. Via des connecteurs spécialisés (Google Drive, S3, Notion), elle peut extraire le contenu brut, le nettoyer et le normaliser avant même qu’il n’atteigne l’entrepôt de données ou le modèle.
Ce support étendu permet de traiter efficacement divers types de sources documentaires :
- Extraction universelle : Capacité à lire et extraire le texte de formats complexes (PDF scannés, présentations PowerPoint, fichiers Markdown).
- Préservation de la hiérarchie : Le pipeline tente de conserver la structure logique du document, un contexte précieux pour la compréhension sémantique par l’IA.
- Traitement de la confidentialité : Des filtres peuvent être appliqués à la source pour anonymiser les données sensibles (PII) avant qu’elles n’entrent dans la chaîne de traitement IA.
Cette capacité permet de déverrouiller le “dark data” de l’entreprise, ces immenses volumes de données inexploitées car non structurées.
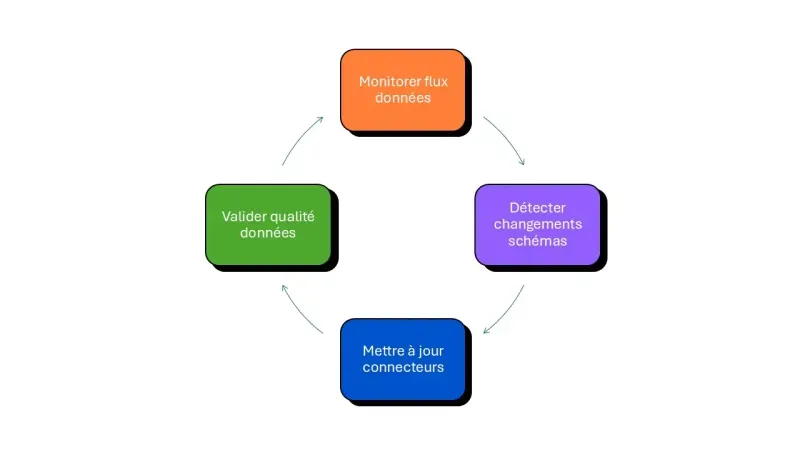
c. L’orchestration et l’observabilité des flux IA
Un pipeline de données pour l’IA ne peut pas être une boîte noire ; la traçabilité est essentielle pour l’explicabilité des modèles.
Airbyte s’intègre nativement avec les outils d’orchestration modernes (Airflow, Dagster, Prefect) et de monitoring data. Cette intégration permet de déclencher les réentraînements de modèles ou les mises à jour d’index vectoriels uniquement lorsque de nouvelles données pertinentes sont disponibles et validées.
L’observabilité et le contrôle des flux sont garantis par plusieurs mécanismes avancés :
- Webhooks et API : Possibilité de déclencher des actions complexes (ex: fine-tuning) via API dès qu’un sync est terminé avec succès.
- Logs structurés : Chaque étape d’extraction et de chargement génère des logs détaillés, permettant de diagnostiquer rapidement pourquoi un modèle hallucine (ex: données sources corrompues).
- Gestion des échecs : Les mécanismes de “retry” automatique et de notification assurent que les pannes transitoires d’API ne cassent pas la chaîne d’apprentissage continu.
Cette robustesse opérationnelle est le prérequis indispensable pour passer des POC (Proof of Concept) à des applications IA en production critiques.
Pour découvrir d’autres usages de l’intelligence artificielle, consultez notre article sur 10 applications concrètes de l’IA générative pour les entreprises.
Cette maîtrise technique des flux prépare le terrain pour aborder les aspects non fonctionnels mais vitaux : la sécurité et la gouvernance dans un contexte open source.
III. Sécurité, souveraineté et gouvernance des données en environnement open source
a. Le contrôle total via l’auto-hébergement (Self-Hosted)
Dans un contexte de guerre économique et de régulations strictes, confier ses données sensibles à un SaaS tiers est un risque que beaucoup ne peuvent plus prendre.
Le modèle open source d’Airbyte permet un déploiement “Self-Hosted” complet, au sein même du VPC (Virtual Private Cloud) de l’entreprise. Les données transitent directement de la source à la destination sans jamais sortir de l’infrastructure contrôlée, garantissant une souveraineté totale.
L’auto-hébergement offre des garanties de sécurité essentielles pour les données critiques :
- Conformité RGPD par design : Aucune donnée ne transite par des serveurs tiers, éliminant les problématiques de transfert de données hors juridiction. Le guide RGPD du développeur publié par la CNIL détaille ces exigences architecturales.
- Sécurité réseau : Possibilité de placer les instances derrière des pare-feux d’entreprise et d’utiliser des rôles IAM stricts pour l’accès aux sources.
- Auditabilité du code : Les équipes de sécurité peuvent auditer chaque ligne de code du moteur d’intégration pour vérifier l’absence de vulnérabilités.
Cette architecture rassure les responsables sécurité et permet de débloquer des projets IA sur des données hautement confidentielles (RH, R&D, financier).
b. Gouvernance et qualité de la donnée en amont
L’adage “Garbage In, Garbage Out” est encore plus critique pour l’IA, où une mauvaise donnée peut biaiser durablement un modèle.
Bien qu’Airbyte soit un outil de mouvement de données, il s’intègre dans une stack moderne incluant dbt pour la transformation et des outils de qualité de données. Pour aller plus loin, découvrez notre approche en audit et diagnostic Data & IA. Il agit comme la première ligne de défense, capable de détecter des changements de schémas (Schema Drift) qui pourraient casser les applications en aval.
Les mécanismes de contrôle qualité intégrés assurent la fiabilité des données ingérées :
- Détection de Schema Drift : Alertes automatiques si la structure des données source change (ex: colonne renommée), évitant l’ingestion silencieuse d’erreurs.
- Typage fort : Conversion et validation des types de données dès l’extraction pour garantir que les entiers restent des entiers et les dates des dates.
- Traçabilité lignage : Intégration avec des outils de catalogue de données pour documenter automatiquement d’où vient la donnée utilisée par l’IA.
Ces fonctionnalités permettent de maintenir un niveau de confiance élevé dans les données alimentant les algorithmes décisionnels.
Pour approfondir les bonnes pratiques de modélisation, consultez notre article sur Comment créer un modèle de données performant : guide complet.
c. Optimisation des coûts d’infrastructure Data & IA
L’intégration de données à haut volume peut rapidement devenir un centre de coût prohibitif, surtout avec des modèles de tarification au volume.
L’approche open source permet de découpler le coût de la licence du volume de données traité. Contrairement aux solutions SaaS facturant à la ligne (“Monthly Active Rows”), Airbyte en version self-hosted ne coûte que l’infrastructure informatique sous-jacente, rendant économiquement viables les projets Big Data.
Le modèle économique open source permet d’optimiser l’investissement infrastructure via :
- Économies d’échelle : Le coût marginal d’extraction d’un téraoctet supplémentaire est minime (hors coût stockage/compute), contre des sommes importantes en SaaS.
- Gestion fine des fréquences : Possibilité d’ajuster la fréquence de sync par connecteur (temps réel vs batch quotidien) pour optimiser la consommation de ressources.
- Choix du compute : Liberté d’exécuter les jobs sur des instances spot ou des clusters existants pour minimiser la facture cloud.
Cette maîtrise des coûts est décisive pour la rentabilité à long terme des projets d’IA générative gourmands en données.
Tableau récapitulatif : Airbyte vs Solutions ETL SaaS classiques pour l’IA
| Critère Stratégique | Solutions ETL SaaS (Fivetran, etc.) | Airbyte (Open Source / Self-Hosted) |
|---|---|---|
| Impact Direct sur vos Projets IA | Coût à l’échelle | Linéaire ou exponentiel (facturation à la ligne) |
| Fixe (coût infra) + Humain | Réduction majeure du TCO sur les gros volumes (logs, IoT). | Données non structurées |
| Support limité ou options payantes complexes | Support natif et extensible via Python | Capacité à exploiter la totalité du patrimoine documentaire pour le RAG. |
| Connecteurs de niche | Dépend de la roadmap de l’éditeur | ”Long Tail” couverte par la communauté |
| Time-to-market accéléré pour les sources de données spécifiques. | Souveraineté des données | Données transitent par le cloud du vendeur |
| Données restent dans votre VPC (100% privé) | Déblocage des cas d’usage IA sur données sensibles (RH, R&D). | Intégration Python |
| Via API complexes | Native via librairie PyAirbyte | Itérations nettement plus rapides pour les équipes Data Science. |
| ### Questions d’auto-diagnostic | Pour évaluer si votre infrastructure actuelle est prête pour l’accélération IA : | 1. Vos Data Scientists passent-ils une part majoritaire de leur temps à écrire des scripts d’extraction de données plutôt qu’à modéliser ? |
| 2. Renoncez-vous à intégrer certaines sources de données pertinentes pour vos modèles à cause du coût prohibitif de votre solution ETL actuelle ? | 3. Votre architecture actuelle vous permet-elle de synchroniser des données non structurées vers une base vectorielle rapidement et sans développement lourd ? |
Besoin d’un accompagnement pour structurer votre stratégie data ? Demandez un diagnostic →
Expertises liées
Besoin d'une feuille de route data ?
Gouvernance, architecture, priorisation des cas d'usage : structurez votre stratégie data avec nos consultants.