IA en local : guide pratique pour déployer un modèle sur vos serveurs
Vos données stratégiques doivent-elles vraiment transiter par des serveurs tiers pour devenir intelligentes ?
Alors que la majorité des décideurs IT placent la souveraineté numérique en tête de leurs priorités, l’hébergement local de modèles d’IA s’impose comme l’alternative incontournable au tout-cloud pour les entreprises soucieuses de leur patrimoine informationnel. Ce guide technique vous détaille comment transformer votre infrastructure existante en forteresse cognitive, sans sacrifier la performance opérationnelle.
I. L’équation économique et sécuritaire : pourquoi internaliser maintenant ?
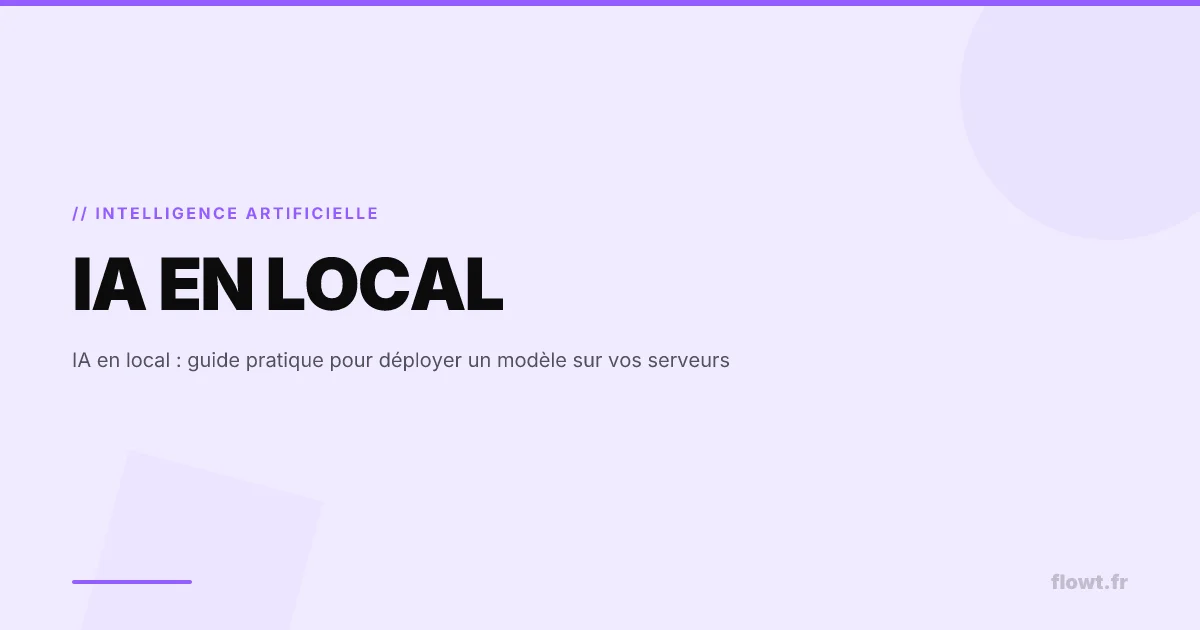
Pourquoi choisir une IA en local ?
a. La souveraineté des données comme impératif non négociable
Dans un contexte où l’espionnage industriel et les fuites d’informations représentent un risque financier considérable pour les entreprises, le déploiement d’une IA en local devient une assurance-vie pour votre capital informationnel. Contrairement aux API publiques qui peuvent ingérer vos prompts pour l’entraînement global, une instance locale garantit que vos secrets industriels restent strictement confinés.
La maîtrise du cycle de vie de la donnée offre plusieurs avantages critiques :
- Confidentialité native : Aucune donnée ne transite sur l’internet public.
- Conformité simplifiée : Vous restez l’unique contrôleur du traitement.
- Isolation totale : Possibilité de fonctionner en environnement déconnecté (air-gapped).
- Auditabilité : Traçabilité complète des accès et des inférences.
Les architectures sur site permettent d’appliquer vos propres politiques de chiffrement et de contrôle d’accès directement au niveau du modèle, assurant une sécurité granulaire impossible à obtenir via une API tierce standardisée.
Pour approfondir les enjeux de déploiement sécurisé, consultez notre article sur Architecture hybride pour LLM : équilibrer performance et sécurité.
b. Latence et performance : la supériorité du traitement en bordure
Au-delà de la sécurité, l’exécution locale élimine les aléas de latence réseau inhérents aux appels API distants. Pour des applications critiques comme l’analyse temps réel sur une ligne de production ou l’assistance au service client, la réactivité immédiate est souvent un prérequis technique absolu.
Voici les gains opérationnels observés sur les déploiements on-premise :
- Latence stable : Temps de réponse constant, non soumis à la charge externe.
- Disponibilité garantie : Aucune dépendance à une connexion internet.
- Débit optimisé : Exploitation directe de la bande passante du réseau interne.
- Prévisibilité : Pas de risque de bridage soudain des performances.
Un modèle bien optimisé tournant sur un serveur GPU dédié peut traiter des requêtes complexes avec une rapidité supérieure aux services cloud standards, améliorant de façon notable l’expérience utilisateur finale.
c. Maîtrise des coûts à l’échelle : CAPEX vs OPEX
Si le ticket d’entrée matériel peut sembler élevé, le modèle économique s’inverse rapidement avec le volume d’utilisation. Le coût par token des API cloud est linéaire, tandis que l’investissement matériel est amortissable et offre un coût marginal par inférence quasi nul.
L’analyse comparative révèle souvent un point de bascule intéressant :
- Pour un usage sporadique, le Cloud reste économiquement pertinent.
- Pour un usage intensif, le local permet une réduction substantielle des coûts opérationnels à moyen terme.
- Le budget devient prévisible plutôt que variable.
- L’optimisation énergétique est sous votre contrôle direct.
La bascule vers une infrastructure interne exige cependant une vision claire de votre stratégie pour justifier l’investissement initial en équipements.
Cette logique de rentabilité et de contrôle nous amène naturellement à poser la question des prérequis techniques : de quelle artillerie avez-vous réellement besoin ?
II. L’arsenal technique : dimensionner votre infrastructure
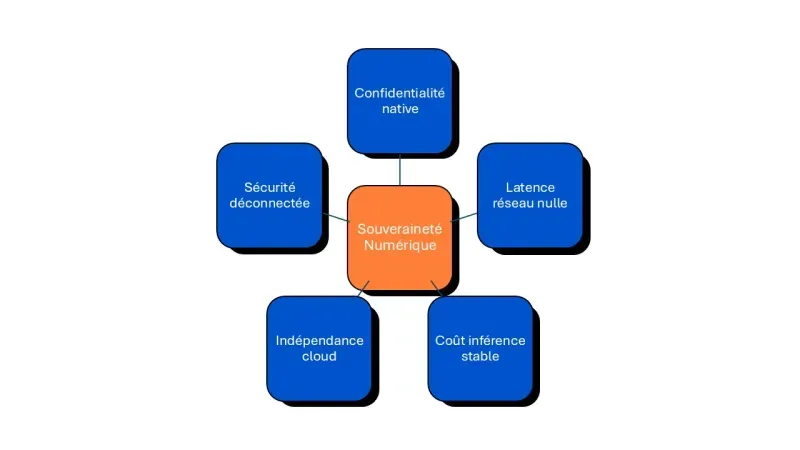
Comment faire pour passer en local ?
a. Hardware : GPU, VRAM et la guerre de la mémoire
Le nerf de la guerre pour faire tourner des LLM (Large Language Models) n’est pas uniquement la puissance de calcul brute, mais surtout la bande passante mémoire et la quantité de VRAM disponible. Un modèle massif ne rentrera jamais sur une carte graphique standard sans une architecture adaptée.
Pour dimensionner correctement, retenez ces ordres de grandeur techniques :
- Modèles compacts (7B/8B) : Tournent confortablement sur des cartes professionnelles d’entrée de gamme.
- Modèles larges (70B) : Nécessitent une mémoire vidéo importante, souvent via le couplage de plusieurs cartes.
- Mixture of Experts (MoE) : Demandent une gestion hybride de la mémoire système et vidéo.
L’erreur classique est de sous-estimer la mémoire nécessaire pour le contexte conversationnel. Une fenêtre de contexte étendue requiert une allocation mémoire supplémentaire significative pour éviter les interruptions de service.
b. La magie de la quantification : GGUF, AWQ et EXL2
Il est rarement nécessaire de faire tourner un modèle dans sa précision originale maximale. La quantification permet de réduire considérablement la taille du modèle avec une perte de qualité imperceptible pour la plupart des tâches métier, rendant l’IA accessible sur des serveurs standards.
Les formats de compression actuels transforment l’accessibilité technologique :
- GGUF : Le standard polyvalent pour faire tourner des modèles sur CPU et GPU.
- AWQ / GPTQ : Optimisés pour l’inférence pure GPU avec un débit élevé.
- EXL2 : Le format rapide pour les cartes modernes, maximisant la vitesse d’inférence.
Grâce à ces techniques, un serveur d’entreprise standard peut aujourd’hui servir des modèles performants pour des tâches de classification ou de résumé, sans nécessiter nécessairement un cluster de calcul intensif.
c. L’orchestration logicielle : Docker, Ollama et vLLM
Le matériel ne fait pas tout ; la couche logicielle détermine la facilité de déploiement et la stabilité de votre service. L’écosystème open source offre désormais des outils matures qui s’intègrent parfaitement dans une pipeline de développement classique.
Les solutions de déploiement à privilégier selon votre maturité technique :
- Ollama : La solution la plus simple pour le prototypage rapide et les tests internes.
- vLLM : Le standard industriel pour la production, offrant un débit jusqu’à 24x supérieur à HuggingFace Transformers grâce à PagedAttention.
- Text-Generation-Inference (TGI) : La solution open source de Hugging Face, robuste et sécurisée pour les environnements exigeants.
L’intégration dans votre système d’information existant se fait généralement via la conteneurisation, permettant d’isoler l’environnement IA tout en facilitant les mises à jour.
Pour structurer votre socle technique, consultez notre article sur Architecture data : comment structurer vos données pour booster votre croissance.
Une fois le moteur installé et ronronnant dans la salle serveur, il reste l’étape décisive : nourrir la bête avec vos propres connaissances.
III. RAG et Fine-tuning : adapter le modèle à votre réalité métier
Veillez à maintenir une optimisation continue de votre architecture IA
a. Le RAG (Retrieval-Augmented Generation) : l’intelligence contextuelle
Un modèle générique ne connaît pas vos clients, vos produits ou vos procédures internes. Plutôt que de réentraîner un modèle complexe, l’approche RAG connecte le cerveau de l’IA à votre base documentaire existante pour ancrer ses réponses dans votre réalité.
Le fonctionnement repose sur une indexation vectorielle dynamique :
- Ingestion : Vos documents et bases de données sont transformés en vecteurs mathématiques.
- Stockage : Ces vecteurs sont sécurisés dans une base dédiée.
- Récupération : Le système retrouve les extraits les plus pertinents pour chaque requête.
- Génération : L’IA formule une réponse factuelle basée sur ces sources.
Cette architecture garantit une fiabilité accrue en réduisant les hallucinations et permet de citer les sources exactes, ce qui est fondamental pour l’adoption en entreprise.
b. Fine-tuning vs Prompt Engineering : choisir son combat
Faut-il réentraîner le modèle ou simplement mieux lui parler ? Dans la grande majorité des cas d’usage PME/ETI, le fine-tuning complet est disproportionné. Il est réservé aux cas où vous devez apprendre au modèle un langage très spécifique ou un format de sortie rigide.
Voici les critères pour orienter votre décision technique :
- Prompt Engineering & RAG : Suffisant pour la plupart des besoins conversationnels et documentaires.
- Fine-tuning léger (LoRA) : Utile pour modifier le style ou le comportement du modèle.
- Pre-training : Réservé à la création de modèles souverains complets.
L’approche d’adaptation légère permet aujourd’hui de spécialiser des modèles open source sur vos tâches spécifiques avec des ressources raisonnables, offrant un excellent compromis performance/investissement.
c. Gouvernance et MLOps : maintenir le système en vie
Déployer est une chose, maintenir en condition opérationnelle en est une autre. Un modèle d’IA en production nécessite une surveillance constante, non pas seulement de son fonctionnement technique, mais de la pertinence de ses réponses dans le temps.
Les piliers d’une maintenance IA durable en entreprise :
- Monitoring de la qualité : Mise en place de boucles de feedback utilisateur.
- Gestion des versions : Traçabilité complète des modèles et des configurations.
- Sécurité continue : Analyse systématique des fichiers modèles pour éviter les vulnérabilités.
- Mise à jour : Capacité à changer de moteur IA sans perturber les applicatifs métiers.
C’est ici que la supervision humaine et procédurale prend tout son sens, évoluant vers une gestion de la conformité algorithmique.
Pour maîtriser le cycle de vie de vos actifs algorithmiques, consultez notre article sur Gouvernance et éthique de l’IA agentique : nouveaux défis pour des agents autonomes.
Tableau récapitulatif : Cloud vs Local pour l’IA d’entreprise
| Critère stratégique | IA Cloud (API publique) | IA locale (on-premise) |
|---|---|---|
| Impact métier direct | Confidentialité | Données exposées au fournisseur (hors contrats spécifiques) |
| Isolation totale, zéro fuite possible | Sécurité absolue pour la R&D et les données RH | Coûts |
| OPEX variable, difficile à prévoir à long terme | CAPEX initial + OPEX stable | ROI positif dès que les volumes deviennent importants |
| Latence | Variable selon la connexion internet | Très faible et constante |
| Expérience utilisateur fluide et temps réel | Contrôle | Nul (modèle boîte noire) |
| Total (choix version, paramètres) | Stabilité des processus métier critiques | Compétences |
| Faibles (intégration standard) | Élevées (Ops, MLOps) | Nécessite une montée en compétence interne |
| ### Auto-diagnostic : Êtes-vous prêt pour l’IA locale ? | 1. Volume : Votre usage actuel des API justifie-t-il un investissement matériel amortissable ? | 2. Sensibilité : Traitez-vous des données critiques, de santé ou des secrets industriels ? |
| 3. Infrastructure : Disposez-vous d’un environnement de virtualisation ou de conteneurisation existant ? | 4. Équipe : Avez-vous les ressources techniques pour gérer des serveurs Linux et des environnements GPU ? | ### Données de marché |
- Selon le rapport McKinsey sur l’état de l’IA en 2024, près de 67% des entreprises identifient la confidentialité des données comme le frein principal à l’adoption de l’IA générative publique.
- Les projections indiquent une croissance annuelle soutenue du marché des infrastructures IA sur site d’ici 2027.
- D’après les benchmarks techniques, l’inférence locale sur des modèles optimisés permet une réduction drastique du coût par token comparé aux tarifs publics pour les gros volumes.
- Les analystes estiment que plus de 40% des DSI s’orientent vers des architectures hybrides pour concilier puissance publique et sécurité privée.
Vous souhaitez intégrer l’IA dans votre entreprise ? Demandez un diagnostic →
Expertises liées
Un projet IA dans votre entreprise ?
De l'IA générative aux agents autonomes, nos experts cadrent et déploient des cas d'usage IA à ROI mesurable.