Chaque jour, 58% des entreprises reconnaissent que leur stack technologique ralentit plutôt qu'elle n'accélère leur prise de décision. Pourtant, la bonne combinaison d'outils BI peut transformer vos données brutes en insights actionnables en quelques heures au lieu de semaines. Le choix d'une stack BI cohérente est un enjeu stratégique directement lié à votre croissance et votre compétitivité. Construire votre stack BI consiste à assembler des briques complémentaires : ingestion, transformation, stockage, et visualisation.
Dans cet article, nous vous proposons un cadre de décision concret, adaptable à la maturité et aux contraintes réelles de votre entreprise.
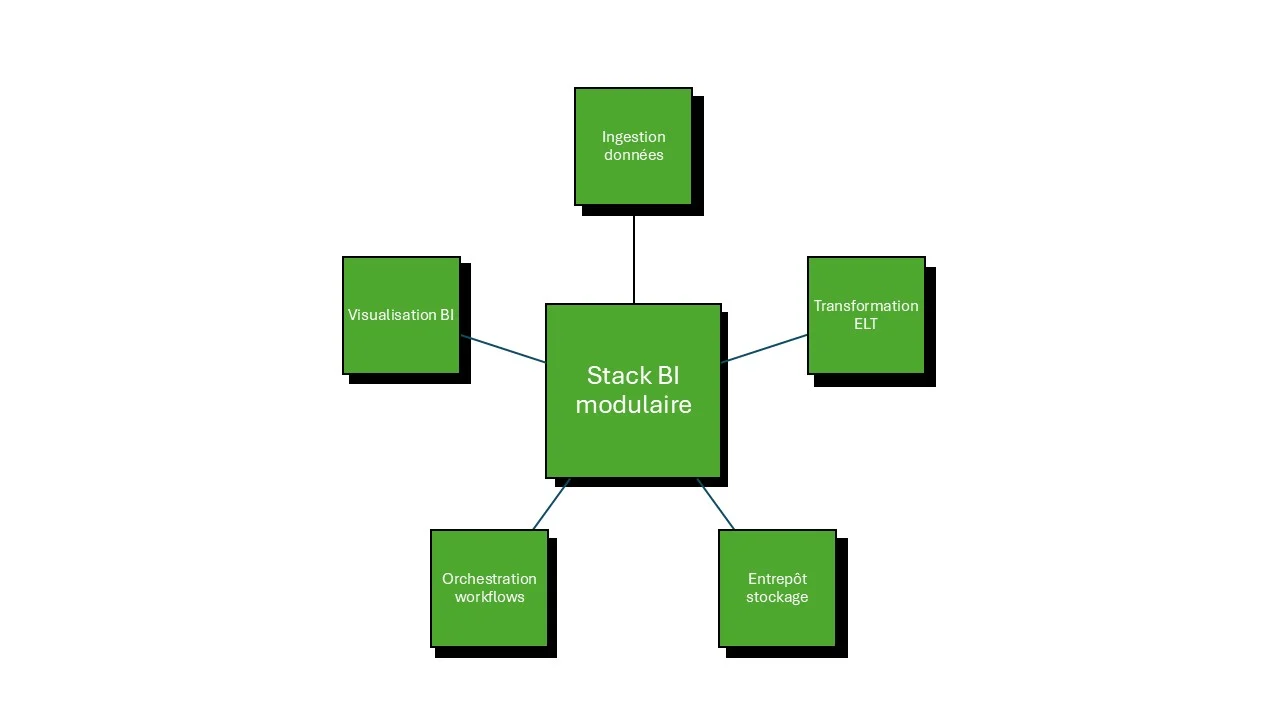
L'ingestion des données demeure la première étape chronophage. Avant de transformer, avant de visualiser, vous devez d'abord centraliser l'information dispersée dans vos applications métier, fichiers Excel, API tierces et bases existantes.
Les outils d'ingestion modernes remplacent les scripts manuels coûteux. Trois familles dominent le marché : les solutions ETL traditionnels (Extract-Transform-Load) qui transforment avant le stockage, les approches ELT inversées (Extract-Load-Transform) qui bénéficient des capacités de calcul du cloud, et enfin les collecteurs d'événements pour les données temps réel.
Capacités critiques à évaluer pour cette couche :
Outils de référence pour l'ingestion : Fivetran (entreprise, coûteux mais robuste), Airbyte (open source flexible), dbt (transformation centralisée sur l'entrepôt). Pour les PME, Extract ou Matillion offrent un bon équilibre coût-facilité d'usage.
Pour approfondir la question, consultez notre article sur ETL vs ELT : Quel pipeline de données choisir pour votre PME ?
Une fois les données centralisées, elles ont besoin d'une « maison » organisée. L'entrepôt de données (data warehouse) n'est pas qu'un simple stockage : c'est l'architecture qui détermine la vitesse de requête, les coûts de scalabilité et votre flexibilité future.
Trois architectures dominent : le data warehouse classique (Snowflake, BigQuery) conçu pour les requêtes analytiques, le data lake pour l'hétérogénéité (données structurées et non structurées mélangées), et les lakehouse hybrides (Databricks) qui combinent les deux approches pour maximiser flexibilité et coûts.
Snowflake s'est imposé comme leader 2025 : architecture cloud-native, séparation calcul/stockage (payer uniquement ce qu'on consomme), excellente gouvernance. BigQuery (Google Cloud) attire par son modèle « pay-as-you-go » sans serveurs. Amazon Redshift convient si vous investissez massivement dans l'écosystème AWS.
Critères de sélection selon votre profil :
Découvrez comment implémenter cette brique via notre guide Mettre en place un data warehouse moderne avec Snowflake pour les PME.
Entre l'ingestion et la visualisation, les données transitent par des dizaines de transformations. Sans orchestration, ces pipelines s'effondrent silencieusement : tâches qui échouent partiellement, données jamais actualisées, alertes qui arrivent trop tard.
L'orchestration automatise l'exécution, les dépendances entre tâches, et les relances en cas d'erreur. Le monitoring détecte proactivement les anomalies (données manquantes, qualité dégradée) avant qu'elles n'impactent vos décisions.
Outils d'orchestration courants :
.webp)
Ces trois outils dominent le marché 2025, mais répondent à des logiques radicalement différentes. Choisir entre eux revient à arbitrer entre trois compromis : coût vs. profondeur analytique, facilité d'usage vs. gouvernance, écosystème propriétaire vs. indépendance technologique.
Power BI propose des fonctionnalités AI/ML intégrées (prédiction, anomalies), prix accessibles, et intégration Microsoft fluide. Mais dès que vos utilisateurs dépassent 500 et vos données 100 To, les coûts d'infrastructure explosent et l'outil atteint ses limites de performance.
Tableau excelle sur la data visualization avancée et l'expérience utilisateur : les graphiques respirent, les interactions semblent naturelles. Ses connecteurs couvrent 80% des sources existantes. Le revers : tarification par utilisateur élevée, et gouvernance moins granulaire que ses concurrents.
Looker (Google) force une approche « model-driven » : vous définissez une unique source de vérité sémantique (via LookML), puis tous les utilisateurs construisent leurs analyses sur cette fondation. C'est rigoureux mais demande de l'expertise au démarrage.
Profil de décision simplifié :
Pour un comparatif détaillé adaptés aux PME/ETI, consultez Tableau vs. Power BI vs. Qlik : comparatif détaillé pour votre stratégie BI.
Tout le BI ne rentre pas dans Power BI. Certains cas d'usage demandent des outils pointus : analytics embarquée (intégrer des dashboards dans votre produit client), real-time decision making (alertes instantanées sur anomalies), self-service analytics (non-techniciens créent leurs propres rapports).
Sisense excelle en analytics embarquée : technologie ElastiCube accélère les requêtes, extensibilité poussée pour développeurs. Domo se positionne sur le pilotage temps réel et connecteurs SaaS. ThoughtSpot propose une interface « search-driven » : les utilisateurs interrogent les données comme un moteur de recherche Google.
Tableau comparatif : les outils BI et leurs cas d'usage optimaux
Au-delà du choix de l'outil émergent une question architecturale : hébergez-vous dans le cloud public (SaaS), sur vos serveurs internes (on-premise), ou combinez-vous les deux (hybride) ?
SaaS cloud : Power BI, Tableau, Looker, Domo sont natives SaaS. Avantages : pas de maintenance, mises à jour automatiques, scalabilité illimitée. Risques : dépendance vis-à-vis du fournisseur, latence réseau potentielle si vos données sont on-premise, coûts d'intégration et migration.
On-premise : déploiement local conserve la maîtrise des données, particulièrement critiqué pour les données fortement réglementées (santé, finance). Qlik Sense, MicroStrategy, Oracle BI proposent cette option. Contrepartie : maintenance coûteuse, équipe IT sollicitée, mises à jour plus lentes.
Hybride : synchronisation d'une copie des données critiques dans le cloud pour les analyses rapides, conservation on-premise pour la source. Diminue la latence et les risques conformité.
Aucune stack n'est universelle. Voici trois architectures réalistes, adaptées à des profils d'entreprise distincts.
Profil 1 : PME industrielle (50-200 employés)
Entrepôt : Snowflake ou BigQuery
Ingestion : Fivetran (simple, prêt à l'emploi)
Orchestration : Apache Airflow ou Prefect (gratuits)
BI : Power BI ou Looker Studio
Coût annuel estimé : 20–40 k€ pour 30 utilisateurs BI
Profil 2 : ETI secteur financier (500+ employés)
Entrepôt : Snowflake (gouvernance, audit trails complets)
Ingestion : dbt + Fivetran (transformations reproductibles)
Orchestration : Airflow + Great Expectations (qualité données)
BI : Looker (model-driven, gouvernance centralisée)
Coûts annuels : 200–400 k€ pour 200 utilisateurs BI + infrastructure
Profil 3 : SaaS B2B intégrant l'analytics
Entrepôt : Databricks Lakehouse (flexibilité multimodale)
Ingestion : Airbyte ou Extract (collecte API massive)
Orchestration : Dagster (workflows modulaires pour produit)
BI : Sisense (embedded analytics dans le produit client)
Coûts annuels : 150–300 k€ pour scalabilité internationale
Caractéristiques partagées : transition ELT (stockage avant transformation), BI décentralisée permettant aux métiers créer leurs analyses, monitoring/observabilité dès J1 (évite surprises coûteuses).
La première erreur : surévaluer l'outil BI avant d'avoir stabilisé l'ingestion. Aucun dashboard ne résout un problème d'données chaotiques. Investissez d'abord dans Fivetran + Snowflake avant de dépenser en Tableau.
Deuxième erreur : acheter des licences massives sans utilisation réelle. Power BI ou Tableau proposent des licences par utilisateur. Trop d'organisations achètent 500 licences « au cas où » : gaspillage. Commencez par 20–50, montez progressivement en fonction de l'adoption réelle.
Troisième erreur : négliger la qualité des données. Un dataset sale génère des insights faux, tuant l'adoption BI auprès des métiers. Budgétisez 25–30% du projet BI sur la gouvernance données et la qualité, non seulement sur les outils flashy.
Points-clés à valider avant acquisition :
.webp)
Plutôt que d'implémenter stack complète en parallèle, un déploiement itératif réduit risques et coûts.
Mois 1–2 : Ingestion + Stockage
Connectez vos trois sources critiques (ERP, CRM, données marketing) à Snowflake via Fivetran. Validez données nettoyées, accessible. Coût : 15–25 k€.
Mois 3 : Orchestration + Monitoring
Automatisez les transformations simples (jointures, agrégations) avec dbt. Pilotez qualité via Great Expectations. Équipe : 1 data engineer à temps plein.
Mois 4–5 : Pilote BI restreint
Créez 5–10 dashboards Power BI / Looker pour les décideurs, basés sur données nettoyées. Testez adoption, retours utilisateurs. Corriger avant large-scale.
Mois 6 : Rollout + Gouvernance
Déploiement progressif aux métiers, formation, documentation. Définissez rôles d'accès, politique de rétention données. Passation au support interne ou partenaire.
Une stack BI complexe sans stratégie données claire reste coûteuse et peu productive. La vraie valeur émerge quand trois éléments s'alignent : une architecture technique solide (ingestion fiable, données de qualité), une gouvernance claire (qui décide quoi, accès, conformité), et une adoption humaine (formation, usage réel, feedback métier).
Les outils évoluent rapidement. Power BI monte en puissance, Looker gagne les clients critiquant la gouvernance, Tableau défend son premium sur l'UX. Ce qui ne change jamais : les meilleurs insights proviennent de données fiables et d'utilisateurs engagés, pas d'une visualisation spectaculaire sur des données mal intégrées.
Vous souhaitez évaluer la bonne stack pour votre maturité actuelle ?
Discutons-en.
Flowt vous accompagne. Experts en Business Intelligence, Data Engineering et Intelligence Artificielle, nous aidons les ETI et grands groupes à exploiter leurs données pour accélérer les décisions et réduire les coûts opérationnels via des stacks technologiques adaptées et optimisées.
Vous souhaitez être accompagné pour lancer votre projet Data ou IA ?


 Perplexity
Perplexity
 ChatGPT
ChatGPT
 Claude
Claude
 Grok
Grok
 Gemini
Gemini
 Mistral
Mistral


