Comment définir votre target operation model pour une stratégie data efficace

Vos équipes accumulent des données dans une dizaine d’outils différents, mais peinent à en tirer des décisions rapides ? Vous investissez dans la Business Intelligence sans constater de gains concrets sur vos indicateurs de performance ? Cette situation révèle l’absence d’un target operating model (TOM) data cohérent, c’est-à-dire d’une architecture opérationnelle qui aligne infrastructure, organisation et gouvernance autour de vos objectifs stratégiques. Un TOM data bien conçu permet aux organisations de réduire substantiellement leurs coûts de traitement tout en accélérant la production d’insights de manière considérable.
I. Cartographier vos besoins métier et vos flux de données
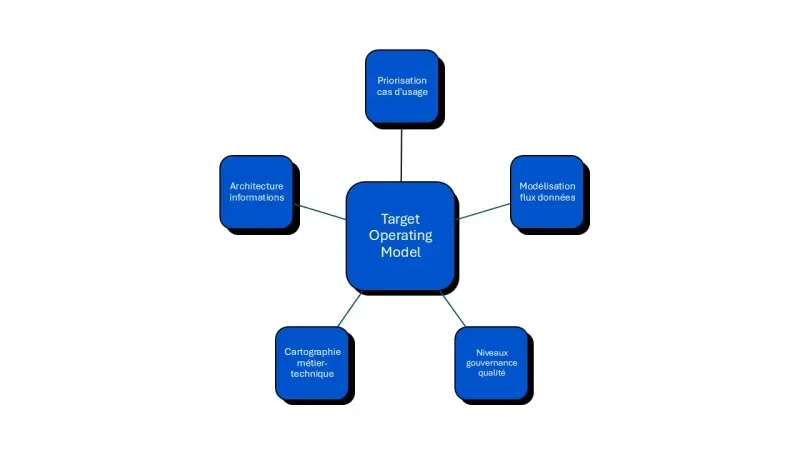
Qu’est ce qu’une TOM ?
a. Identifier les cas d’usage prioritaires par fonction
Démarrer par une cartographie exhaustive des besoins métier évite la dispersion des ressources. Interrogez directement les directions opérationnelles pour recenser les décisions critiques nécessitant un appui data : prévision des ventes, optimisation des stocks, pilotage de la rentabilité client ou détection d’anomalies. Selon les benchmarks sectoriels, les entreprises qui priorisent une poignée de cas d’usage stratégiques obtiennent un retour sur investissement nettement supérieur à celles qui multiplient les projets exploratoires sans hiérarchie claire.
Les critères de priorisation doivent intégrer à la fois l’impact métier et la faisabilité technique. Pour valider vos choix, soumettez chaque cas d’usage à ces questions d’auto-diagnostic :
- Ce cas d’usage impacte-t-il directement un objectif stratégique de l’année (ex: marge, churn) ?
- Les données sources sont-elles accessibles et historisées depuis au moins 12 mois ?
- L’équipe métier est-elle prête à modifier ses processus suite aux résultats ?
- Le ROI est-il mesurable à moins de 6 mois ?
Les analyses de marché confirment que concentrer les efforts sur 3 à 5 chantiers prioritaires maximise l’adoption utilisateur et démontre rapidement la valeur créée, facilitant le déploiement futur.
b. Modéliser les flux de données de bout en bout
La compréhension fine des flux de données constitue le socle d’un target operating model robuste. Tracez le parcours complet de chaque donnée critique, depuis sa source (ERP, CRM, capteurs IoT) jusqu’à sa consommation dans les tableaux de bord. Les études du secteur montrent qu’une majorité de projets BI échouent faute de visibilité sur les dépendances entre systèmes et sur les transformations appliquées aux données.
Documentez systématiquement les éléments structurants de vos flux en suivant ces étapes concrètes :
- Identifier les systèmes sources (SaaS, On-premise, fichiers plats) et leur fréquence de mise à jour.
- Cartographier les règles de transformation et d’agrégation appliquées (ETL/ELT).
- Localiser les points de stockage intermédiaires (data lake, data warehouse).
- Lister les consommateurs finaux et le niveau de latence acceptable pour chaque métier.
Cette modélisation rigoureuse permet généralement de détecter des redondances de traitement majeures. La consolidation de ces flux réduit les coûts de maintenance et améliore la cohérence globale des reportings.
Pour approfondir les méthodes de structuration, consultez notre article sur Data engineering vs data architecture : rôles et synergies en PME.
c. Définir les niveaux de gouvernance et de qualité requis
Les exigences de gouvernance varient selon la sensibilité des données et les contraintes réglementaires. Définissez pour chaque flux son niveau de criticité (stratégique, opérationnel, support) et les règles de qualité associées. Les organisations matures appliquent des seuils de qualité différenciés, évitant ainsi de sur-ingéniériser les données à faible impact métier tout en garantissant la fiabilité des indicateurs clés.
Structurez votre gouvernance autour de rôles clairs et de processus documentés. Les bonnes pratiques recommandent de mettre en place :
- Des Data Owners identifiés au sein des métiers, responsables de la définition des données.
- Des Data Stewards garants de la qualité et du dictionnaire de données au quotidien.
- Un catalogue de données centralisé et accessible à tous les analystes.
- Des workflows de validation pour toute modification de règle de calcul.
L’instauration d’un scoring de qualité à la source (Data Quality Score), couplé à des alertes automatisées, constitue le levier le plus efficace pour réduire drastiquement les incidents de production et restaurer la confiance des utilisateurs.
Cette cartographie métier et technique soulève désormais la question de l’architecture technologique et organisationnelle permettant de la concrétiser efficacement.
II. Concevoir l’architecture technologique et organisationnelle
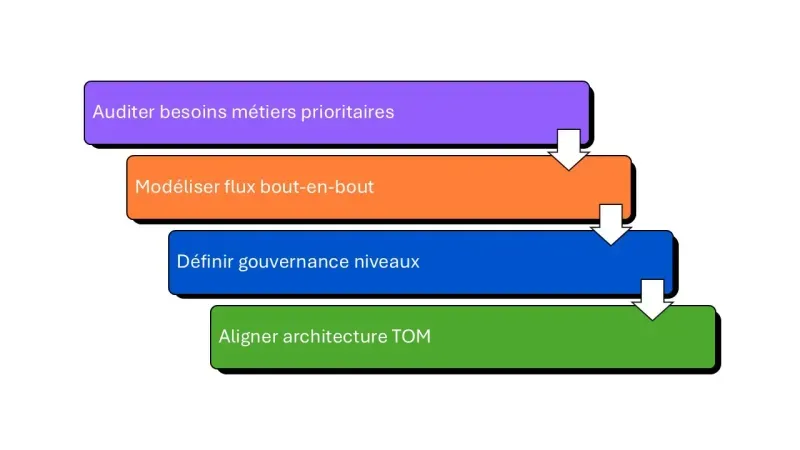
Pas à pas vers une TOM opérationelle
a. Choisir les briques technologiques adaptées à votre maturité
Votre stack technologique doit refléter votre niveau de maturité data et vos contraintes budgétaires. Les entreprises en phase initiale privilégient des solutions intégrées offrant un time-to-value rapide, tandis que les organisations matures investissent dans des architectures modulaires combinant data warehouse cloud et outils spécialisés. Selon les retours d’expérience du secteur, le choix d’une stack inadaptée génère un surcoût significatif sur la maintenance.
Évaluez vos options technologiques à l’aide de cette grille de décision :
- Scalabilité : La solution supporte-t-elle une multiplication par 10 des volumes sans refonte ?
- Interopérabilité : Les connecteurs natifs couvrent-ils 80% de vos sources actuelles ?
- Autonomie : L’interface permet-elle aux utilisateurs métier de créer leurs propres vues (Self-Service) ?
- Coût total : Le modèle de pricing (au stockage ou à la requête) est-il prédictible ?
Une architecture bien dimensionnée divise souvent par deux ou trois les délais de mise à disposition de nouveaux indicateurs par rapport aux infrastructures héritées.
Pour approfondir le choix des outils, consultez notre article sur Quelle stack pour votre Business Intelligence ?.
b. Structurer les rôles et responsabilités data
Un target operating model performant repose sur une organisation claire des rôles data. Définissez la répartition entre fonctions centralisées (data engineers, data architects) et décentralisées (analystes métier). Les modèles hybrides, ou “Hub & Spoke”, combinant un centre d’excellence technique et des relais métier, génèrent les meilleurs résultats selon les analyses du marché.
Les responsabilités doivent couvrir l’intégralité du cycle de vie de la donnée. Assurez-vous de couvrir ces fonctions clés :
- Data Engineers : Pipeline, ingestion et fiabilisation technique.
- Analytics Engineers : Modélisation et transformation pour le métier (dbt, SQL).
- Data Analysts : Construction de dashboards et exploration.
- Data Governance Managers : Conformité, sécurité et documentation.
Cette structuration évite l’effet “goulot d’étranglement” de l’IT centralisée et permet de multiplier le nombre de cas d’usage déployés en parallèle.
c. Établir les processus de collaboration et de partage
Les processus collaboratifs conditionnent l’efficacité du TOM data au quotidien. Formalisez les rituels de synchronisation entre équipes data et métier pour éviter l’effet “boîte noire”. Les organisations qui instaurent des cadences structurées constatent une réduction majeure des projets ne répondant pas aux attentes initiales.
Développez une culture de la donnée à tous les niveaux via ces actions concrètes :
- Instaurer des revues de roadmap trimestrielles avec les sponsors métier.
- Organiser des “Data Demos” mensuelles pour présenter les nouveautés à toute l’entreprise.
- Mettre en place un canal de support réactif (Slack/Teams) dédié aux questions data.
- Documenter chaque dataset publié avec un “ReadMe” compréhensible par un non-technicien.
L’objectif est de passer d’une relation client-fournisseur interne à un véritable partenariat où les métiers s’approprient leurs données.
Cette organisation technologique et humaine soulève maintenant la question de la mesure de performance et de l’évolution continue du modèle opérationnel.
III. Piloter la performance et faire évoluer le modèle
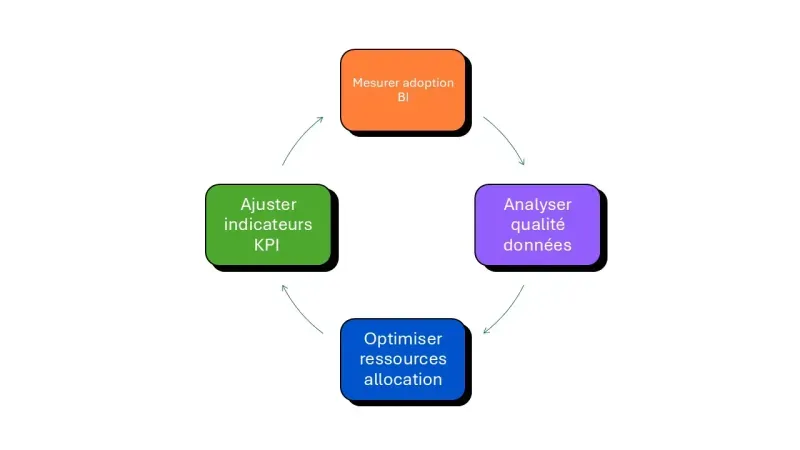
Une TOM n’est efficace que si elle est maintenue en bonne santé
a. Définir les indicateurs de succès du TOM data
Mesurer l’efficacité de votre target operating model exige des métriques alignées sur vos objectifs stratégiques. Distinguez les indicateurs d’usage (nombre d’utilisateurs actifs) des indicateurs d’impact métier (valeur générée). Les cabinets de conseil observent que les entreprises pilotant leur TOM data via des KPI d’impact obtiennent un retour sur investissement nettement supérieur à celles se concentrant uniquement sur la technique.
| Indicateur | Benchmark cible | Impact ou Levier | Action corrective |
|---|---|---|---|
| Adoption (Active Users / Total) | 60-75% | Démocratisation réelle de la data | Renforcer la formation et l’UX design |
| Qualité (Data Quality Score) | >95% | Confiance dans les décisions | Audit des sources et règles de validation |
| Vélocité (Time-to-Insight) | <48h | Agilité face au marché | Modulariser l’architecture et DataOps |
| ROI (Valeur générée / Coût) | >200% (3 ans) | Pérennité du budget data | Prioriser les cas d’usage à fort impact P&L |
Piloter ces indicateurs mensuellement permet d’identifier rapidement les freins à l’adoption et d’ajuster la stratégie de formation ou l’architecture technique.
Pour approfondir la mesure de la performance, consultez notre article sur Indicateurs clés pour piloter la performance data en PME.
b. Anticiper les évolutions technologiques et métier
Votre target operating model doit intégrer une dimension prospective pour absorber les transformations à venir. Évaluez régulièrement les innovations technologiques (IA générative, Data Fabric) et leur pertinence pour vos enjeux. Les benchmarks montrent que réserver une part du budget à l’innovation (10-15%) permet de maintenir un avantage concurrentiel durable.
Structurez votre veille technologique et métier en vous posant ces questions trimestrielles :
- Quelles nouvelles sources de données externes pourraient enrichir nos analyses ?
- Nos outils actuels freinent-ils certains nouveaux besoins (ex: temps réel) ?
- De nouvelles régulations (AI Act, RGPD) impactent-elles notre gouvernance ?
- L’architecture est-elle prête pour intégrer des modèles d’IA générative ?
Cette approche proactive permet d’identifier les opportunités d’enrichissement des modèles, comme l’intégration de données open data économiques pour affiner les prévisions commerciales.
c. Orchestrer la conduite du changement continue
La pérennité de votre TOM data repose sur une conduite du changement permanente. Dépassez la logique de grands projets “Big Bang” pour adopter une approche itérative, déployant de nouvelles capacités tous les deux à trois mois. Cette agilité favorise une appropriation utilisateur bien plus forte et réduit le risque d’obsolescence.
Pour ancrer durablement le changement, appliquez ces principes :
- Lancer des “Quick Wins” pour démontrer la valeur sur des irritants connus en moins de 4 semaines.
- Identifier et valoriser des “Ambassadeurs Data” dans chaque département.
- Mettre en place des boucles de feedback systématiques après chaque livraison.
- Communiquer sur les succès (et les échecs) pour maintenir la dynamique.
La conduite du changement n’est pas une étape finale mais un processus continu qui garantit l’alignement permanent entre les capacités de la plateforme data et les besoins réels du terrain.